
The contents in this post are excerpted from the paper “YOLOv3: An Incremental Improvement” 1, with a little bit modification, as my notes for this paper.
Also refer to:
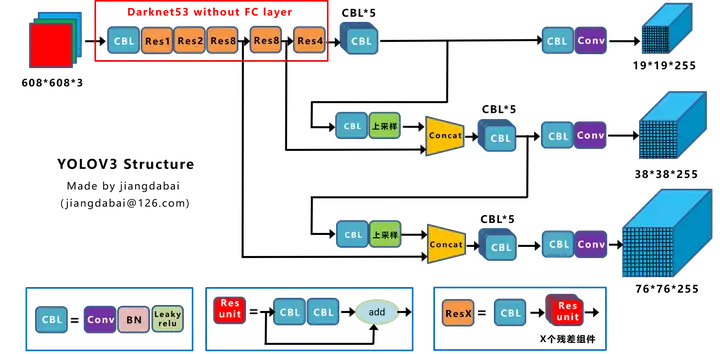
2. The Deal
2.1. Bounding Box Prediction
Use anchors.
2.2. Class Prediction
We use independent logistic classifiers to predict classes instead of a softmax. In another word, we use multilabel classification instead of multiclass classification. During training we use binary cross-entropy loss.
In this dataset there are many overlapping labels (i.e. Woman and Person). Using a softmax imposes the assumption that each box has exactly one class which is often not the case. A multilabel approach better models the data.
2.3. Predictions Across Scales
YOLOv3 predicts boxes at 3 different scales. Our system extracts features from those scales using a similar concept to feature pyramid networks (FPN).
2.4. Feature Extractor
Use Darknet-53.
Darknet-53 has similar performance to ResNet-152 and is 2 times faster. ResNets have too many layers and are not very efficient.
3. How We Do
With FPN, YOLOv3 has relatively high \(\text{AP}_S\) performance, i.e. it is good at detecting small objects. However, it has comparatively worse performance on medium and larger size objects.
Reference:
-
Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018). ↩