
The contents in this post are excerpted from the paper “Spatial pyramid pooling in deep convolutional networks for visual recognition” 1, with a little bit modification, as my notes for this paper.
Abstract
CNN requires a fixed-size input. SPP generates a fixed-length representation regardless of input size.
For object detection tasks, SPP-net is faster than R-CNN. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features.
1. Introduction
A CNN mainly consists of two parts: convolutional layers, and fully-connected layers that follow. The fixed-size constraint comes only from the fully-connected layers, while the convolutional layers accept inputs of arbitrary sizes.
In this paper, the authors introduce a spatial pyramid pooling (SPP) layer to remove the fixed-size constraint of the network. Specifically, the authors add an SPP layer on top of the last convolutional layer. The SPP layer pools the features and generates fixed- length outputs, which are then fed into the fully-connected layers (or other classifiers). In other words, the authors perform some information “aggregation” at a deeper stage of the network hierarchy (between convolutional layers and fully-connected layers) to avoid the need for cropping or warping at the beginning.


SPP has several remarkable properties for deep CNNs compared to the sliding window pooling:
- SPP is able to generate a fixed-length output regardless of the input size, while the sliding window pooling cannot;
- SPP uses multi-level spatial bins, while the sliding window pooling uses only a single window size. Multi-level pooling has been shown to be robust to object deformations;
- SPP can pool features extracted at variable scales thanks to the flexibility of input scales.
SPP-net not only makes it possible to generate representations from arbitrarily sized images/windows for testing, but also allows us to feed images with varying sizes or scales during training. Training with variable-size images increases scale-invariance and reduces over-fitting.
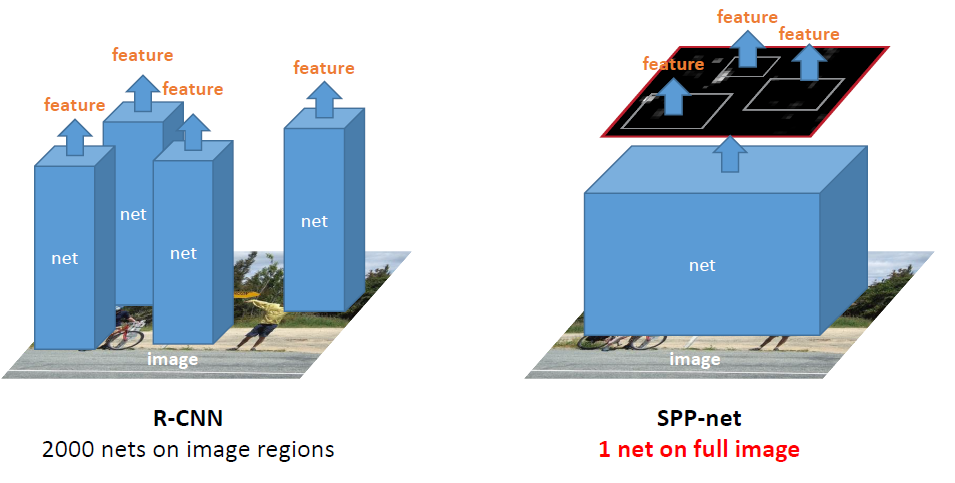
As for object detection, the feature computation in R-CNN is time-consuming, because it repeatedly applies the deep convolutional networks to the raw pixels of thousands of warped regions per image. SPP-net run the convolutional layers only once on the entire image (regardless of the number of windows), and then extract features by SPP layer on the feature maps. This method yields a speedup of over one hundred times over R-CNN, while has better or comparable accuracy.
2. Deep Networks with Spatial Pyramid Pooling
2.2 The Pyramid Pooling Layer
As for the pooling layer, the ouput size is always proportional to the input size. In SPP-net, we make the pooling window size (spatial bin size in SPP-net) and stride proportional to the input size, then we get an output of fixed size (the number of bins in SPP-net) regardless of the input size.

2.3 Training the Network
Consider the feature maps after \(\mathrm{conv}_{5}\) that have a size of \(a \times a\) (e.g., \(13 \times 13\)). With a pyramid level of \(n \times n\) bins, we implement this pooling level as a sliding window pooling, where the window size \(\mathrm{win} = \lceil a / n \rceil\) and stride \(\mathrm{str} = \lfloor a / n\rfloor\) with \(\lceil\cdot\rceil\) and \(\lfloor\cdot\rfloor\) denoting ceiling and floor operations. With an \(l\)-level pyramid, we implement \(l\) such layers. The next fully-connected layer (\(\mathrm{fc}_{6}\)) will concatenate the \(l\) outputs.
5. Conclusion
SPP is a flexible solution for handling different scales, sizes, and aspect ratios.
Reference:
-
He, Kaiming, et al. “Spatial pyramid pooling in deep convolutional networks for visual recognition.” IEEE transactions on pattern analysis and machine intelligence 37.9 (2015): 1904-1916. ↩