
Stacking (or stacked generalization) is one of the three widely used ensemble methods in Machine Learning. The overall idea of stacking is to train several models (base learners, or level-0 models), usually with different algorithm types, on the train data, and then rather than picking the best model, using another model (meta learner, or level-1 model) to learn how to best combine the predictions from the base learners, to make the final prediction. The inputs for the meta-learner is the prediction outputs of the base-learners.

At first, we train the base learners by the original data, and use the predictions of these base learners as the features and the original labels as the target to train the meta learner.
To reduce overfitting, the most common approach to preparing the training dataset for the meta-model is via \(K\)-fold cross-validation of the base models, where the out-of-fold predictions are used as the training dataset for the meta model.
Say the original dataset has \(N\) samples and we want to train \(M\) types of base learners. After \(K\)-fold cross-validation, we have \(K \cdot M\) models. The out-of-fold predictions made by these models compose a matrix of dimension \(N \times M\), and we use this matrix and the original labels (as shown below) to fit the meta-learner.
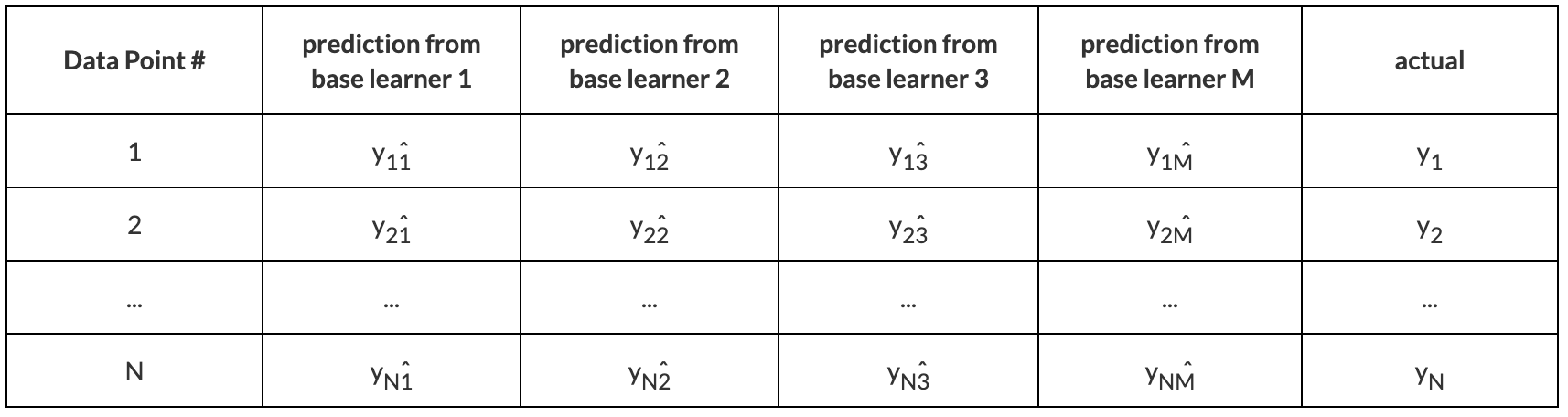
Note that we have \(M\) types of base-learners and each has \(K\) models, so we have \(K \cdot M\) models. After the meta learner has been trained. We can keep all these \(K \cdot M\) models at level-0. In this situation, for an input test sample, the \(K\) models in each type of base-learners produce \(K\) predictions, and we make an average of them. Then the output of the level-0 is a vector of dimension \(M\), and this output is the input of level-1 meta-learner.
The following figure is an example of stacking, where we have only one type of base learner, and make \(5\)-fold cross-validation to fit \(5\) models at level-0. We use these \(5\) models to make predictions on test data and take average of them as the input of the meta-learner (model 6 in the figure).
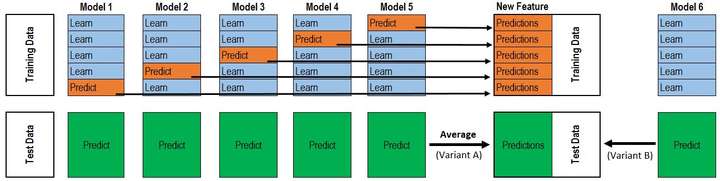
For computational simplicity, rather than keep all \(K \cdot M\) models at level-0, we usually fit \(M\) models by whole training dataset as the final base learners.
We usually use a simple model as the meta-learner, like Linear Regression or Logistic Regression, to reduce overfitting.
References: